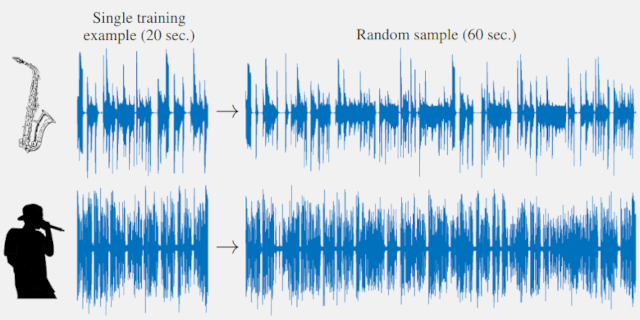
Models for audio generation are typically trained on hours of recordings. Here,
we illustrate that capturing the essence of an audio source is typically possible from as little as a
few
tens of seconds from a single training signal. Specifically, we present a GAN-based generative model
that
can be trained on one short audio signal from a ny domain (e.g.speech, music, etc.) and does not require
pre-training or any other form of external supervision. Once trained, our model can generate
random samples of arbitrary duration that maintain semantic similarity to the training waveform, yet
exhibit new compositions of its audio primitives. This enables along line of interesting applications,
including generating new jazz improvisations or new a-cappella rap variants based on a single short
example, producing coherent modifications to famous songs (e.g.adding a new verse to a Beatles song
based solely on the original recording), filling-in of missing parts (inpainting), extending the
bandwidth
of a speech signal (super-resolution), and enhancing old recordings without access to any clean training
example. We show that in all cases, no more than 20 seconds of training audio commonly suffice for our
model to achievestate-of-the-art results. This is despite its complete lack of prior knowledge about the
nature of audio signals in general.
Catch-A-Waveform: Waveform generation from a single short example
Catch-A-Waveform's Applications
Catch-A-Waveform: Waveform generation from a single short example
Catch-A-Waveform's Applications
Unconditional Generation
Unconditional generation of different signal types with arbitrary sizes.
Monophonic Music
Instrument
Input (Real)
Fake (20 [sec])
Fake (40 [sec])
Fake (60 [sec])
Speech Signals
Input (Real)
Fake (20 [sec])
Fake (40 [sec])
Fake (60 [sec])
Ambient Sounds
Input (Real)
Fake (20 [sec])
Fake (40 [sec])
Fake (60 [sec])
Effect of Receptive Field
Demonstration of creating speech signals, with different receptive field sizes.
training length [sec]
Input (Real)
Small Receptive Field 2[sec]-60[ms]
Normal Receptive Field 4[sec]-120[ms]
Large Receptive Field 8[sec]-240[ms]
Music Variations
Training on famous songs, and then creating different variations on these
songs.
Name
Artist
Input (Real)
Fake 1
Fake 2
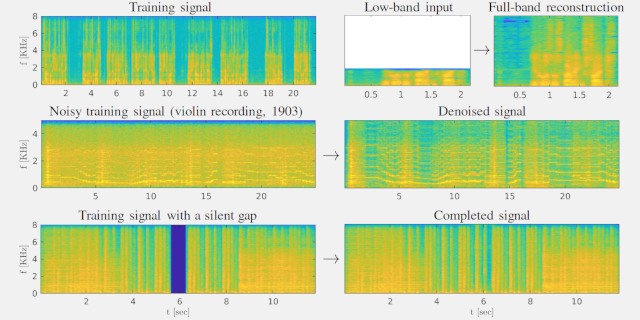
Bandwidth Extension
In this section there are bandwidth extention examles on VCTK [3] dataset, compared
to TFiLM [2] model. For each examples there are six signals; In the upper row (left to right):
low-resolution version, ground-truth high resolution signal, the signal used for training our model
(20-25 [sec]); In the lower row: extended with TFiLM model trained on single speaker (30 [min]),
extended with TFiLM model trained on multi speaker (600 [min]), extended with our model.
4Khz -> 16KHz Extensions
8Khz -> 16KHz Extensions
When we perform bandwidth extension for wider-bandwidth inputs, we are able to get much better and
clearer
results. Here are some examples where the input signals are sampled at 8Khz.
Inpainting
Completing a missing part in a given signal in rock songs. Comparison between
GACELA [1] model (trained on 8 [hours]) and ours (trained on 12 [sec]).
Input
GT
GACELA
Ours
Denoising
In this part, we demonstrate denoising old recording by famous violinist Joseph Joachim. Click on the
play/pause button next to each example. You can switch between the noisy and denoised version by
clicking the "switch" button.
Denoising Synthesized Noisy Signals
In order to measure the SNR improvements of denoised signals, we took a clean
recording of Bach's Adagio played by violinist Hilary Hahn and added to it white
noise and old gramophone
noise in two noise levels. You can listen to the input and reconstructed sounds, where the SNR
levels and noise types are written above the spectrograms.
Limitations
Here are some examples where our model created signals of degraded quality.

 Catch-A-Waveform: Waveform generation from a single short example
Catch-A-Waveform: Waveform generation from a single short example
 Catch-A-Waveform's Applications
Catch-A-Waveform's Applications